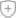-
监管机构

-
银行

-
租赁

-
其他金融





时间:2021-01-20
讲到数据治理,我们经常提到的一个词就是血缘分析,那么什么是血缘分析呢?一句话来说血缘分析是保证数据融合(聚合)的一个手段,通过血缘分析实现数据融合处理的可追溯。
有时被概念瞎蒙了,不知道到底如何追溯,落不了地。本人接触的数据治理项目还主要是将各个来源的数据进行整理融合,形成人地事物组织几个业务大类数据。
在现实世界中,我们每个个体都是祖先通过生育关系一代代孕育而来,这样就形成了我们人类的各种血缘关系。在数据信息时代,我们庞大的数据在每时每刻产生,这些数据又经过各种加工组合、转换,又会产生新的数据,这些数据之间就存在着天然的联系,我们把这些联系称为数据血缘关系。
大数据数据血缘是指数据产生的链路。直白点说,就是我们这个数据是怎么来的,经过了哪些过程和阶段。举个例子,比如在生产系统如淘宝网中,客户在淘宝网页中购买物品后,数据就被存到后台数据库表A中。当我们领导需要查看某个月卖的最火的是哪些物品时,我们需要对存入的这些数据进行加工汇总,形成一张新的表B来存储我们处理的数据,最后我们会根据B表进一步处理成我们前台展现使用的表C。那么A表是C表数据最初的来源,是C表数据的祖先。从A表数据到B表数据在到C表数据,我们认为这条链路就是C表的数据血缘。
在数据的处理过程中,从数据源头到最终的数据生成,每个环节都可能会导致我们出现数据质量的问题。比如我们数据源本身数据质量不高,在后续的处理环节中如果没有进行数据质量的检测和处理,那么这个数据信息最终流转到我们的目标表,它的数据质量也是不高的。也有可能在某个环节的数据处理中,我们对数据进行了一些不恰当的处理,导致后续环节的数据质量变得糟糕。因此,对于数据的血缘关系,我们要确保每个环节都要注意数据质量的检测和处理,那么我们后续数据才会有优良的基因,即有很高的数据质量。
如上图所示,在生成指标B的过程,输入表A进行了变更,如果通过血缘分析,了解到了A所影响的路径范围,那么完全不必要重新做一次所有计算任务,而只是把A到B之间影响到的节点重新加工即可。这样计算量可以大大缩减,而且提高任务的弹性时间,或许1小时内就能完成调整后的计算。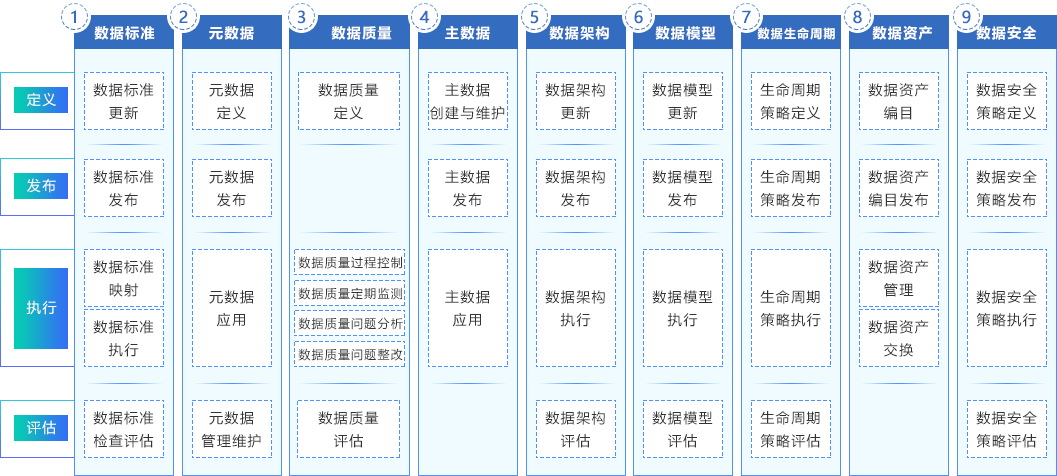
华宇智能数据数据治理解决方案
华宇智能数据拥有专业的数据治理能力框架以及数据治理统一流程、数据治理成熟度评估模型等方法论和项目经验支撑。从数据治理实施落地路径上来讲,应该是自下而上推进,梳理系统数据现状,明确数据存在的问题,制定具体数据标准规范统一数据统计口径,完成数据整合管理等等,推进优化业务应用设计和数据模型,进而推动业务数据架构不断创新,形成闭环。

融资租赁作为金融行业五大支柱之一,是直接支持实体经济发展的金融服务手段,能够盘活企业存量资产,降低企业负债,在现代金融产业中占据着重要的地位。

大数据风控的三要素:场景、数据算法、人。场景是风控融于实际租赁业务,真正发挥风控价值;数据与算法,缺一不可,只有二者结合起来才能通过算法发掘数据中的风控规则;人,作为风控系统的操盘手,是真正发挥大数据风控的关键因素。

存储设备作为银行数据中心内最关键的硬件资源,其重要性不言而喻。随着数据中心发展规模的不断壮大,存储设备升级扩容、更新换代甚至是存储架构的整体变革是存储工程师工作内容中重要的一环。本文通过对存储选型自身的需求分析、存储选型指标体系的设计建立以及最终进行存储产品的选型指标参数对比方面进行阐述,希望能对存储工程师在存储选型工作上提供一定的方法论和经验指导。